
로컬 환경에서 단일 클러스터로 Apache Spark를 설치하기 위해서는
1. JDK 설치
2. Python 설치
3. Apache Spark 설치
4. Hadoop Winutil 설치
5. 시스템 환경변수 설정
이렇게 총 5단계를 거쳐야 한다.
1. JDK 설치
Apache Spark는 Scala로 구현되어 있고 JVM 위에서 동작하기 때문에 Java를 먼저 설치해주어야 한다.
본인의 경우, 원래 Java 17 환경이 세팅되어 있었는데 version 때문인지 Spark 실행이 되지 않아 11.0.18로 재설치 해주었다.
Download the Latest Java LTS Free
Subscribe to Java SE and get the most comprehensive Java support available, with 24/7 global access to the experts.
www.oracle.com
위 링크로 접속해서 로그인한 후 스크롤을 내리다보면
이렇게 Java 11 버전에 대한 설치 안내가 나온다.
자신의 OS를 선택한 후, 절차에 따라 설치해준다.
설치가 완료되면 터미널을 실행하여 다음 명령어를 통해 정상적으로 설치가 진행되었는지 확인한다.
# java 버전 확인
java -version
정상적으로 설치가 완료되었다면, 다음과 같이 설치된 java의 버전 정보가 출력된다.
그런데 여기서 본인처럼 원래 세팅된 java 환경이 있으면 버전이 바뀌지 않는 경우가 있는데 이런 경우에서의 해결 방법은 따로 포스팅하겠다.
추가적으로 시스템 환경변수에 JAVA_HOME을 등록해준다.

이렇게 해서 java 설치를 완료했다.
2. Python 설치
본인은 이미 Python 3.10 환경이 구축되어 있어서 본 단계를 건너뛰겠다.
Python 설치가 안되어 있는 분들은 3.8 버전 이상의 Python을 설치해주면 된다.
3. Apache Spark 설치
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS by following these procedures. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides
spark.apache.org
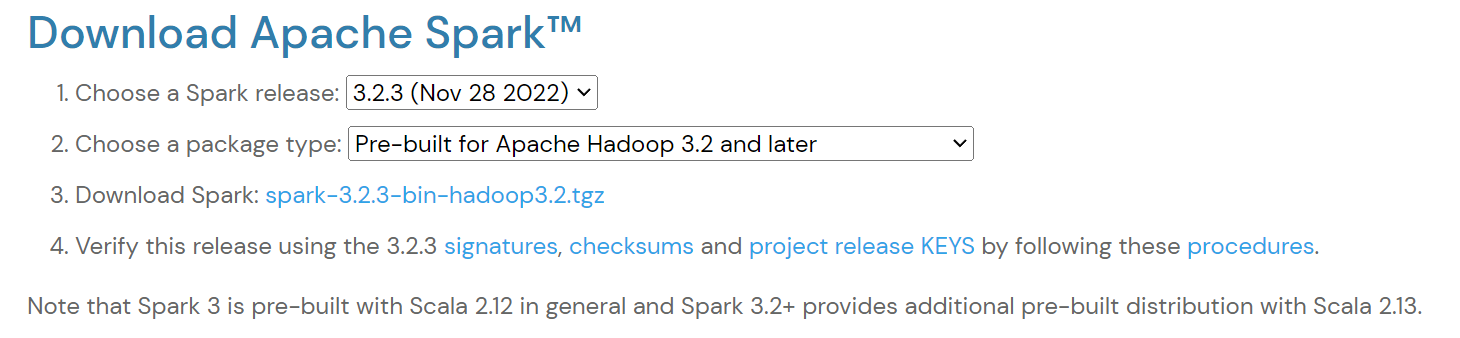
Apache Spark 설치를 위해서 위 링크에 접속한 후에 설치하고자 하는 버전을 선택하여 압축 파일을 다운로드한다.
최신 버전은 3.3.1이지만 hadoop winutil이 3.2 버전만 존재하여 3.2.3 버전으로 다운로드 해주었다.
설치하고자 하는 디렉토리에 압축을 해제해준다.
GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows
winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows - GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows
github.com
다음으로 hadoop winutil 설치를 위해서 위 링크에 접속한 후에 설치한 Apache Spark 버전이 필요로 하는 hadoop 버전에 해당하는 winutil을 원하는 디렉토리에 다운로드 해준다.
5. 시스템 환경 변수 설정
실행을 위해서 SPARK_HOME과 HADOOP_HOME을 등록해야 하므로, 시스템 환경 변수 편집으로 들어가서 시스템 변수에 Apache Spark와 winutil이 설치된 경로를 등록해준다.
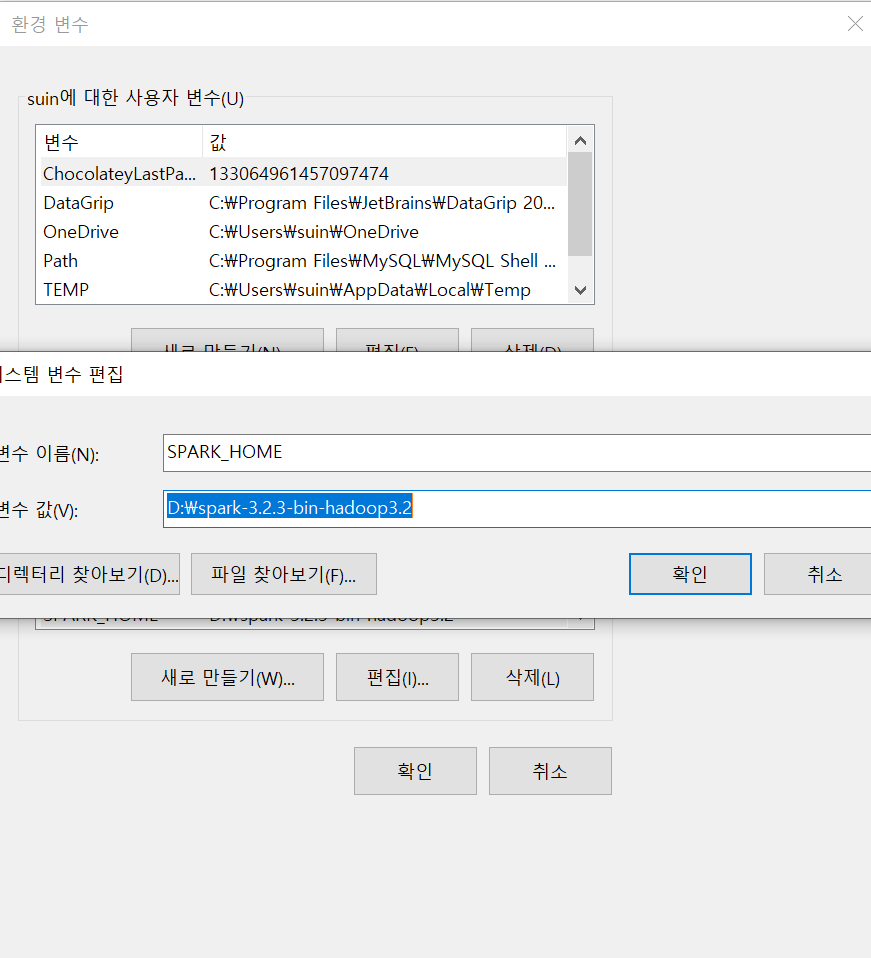
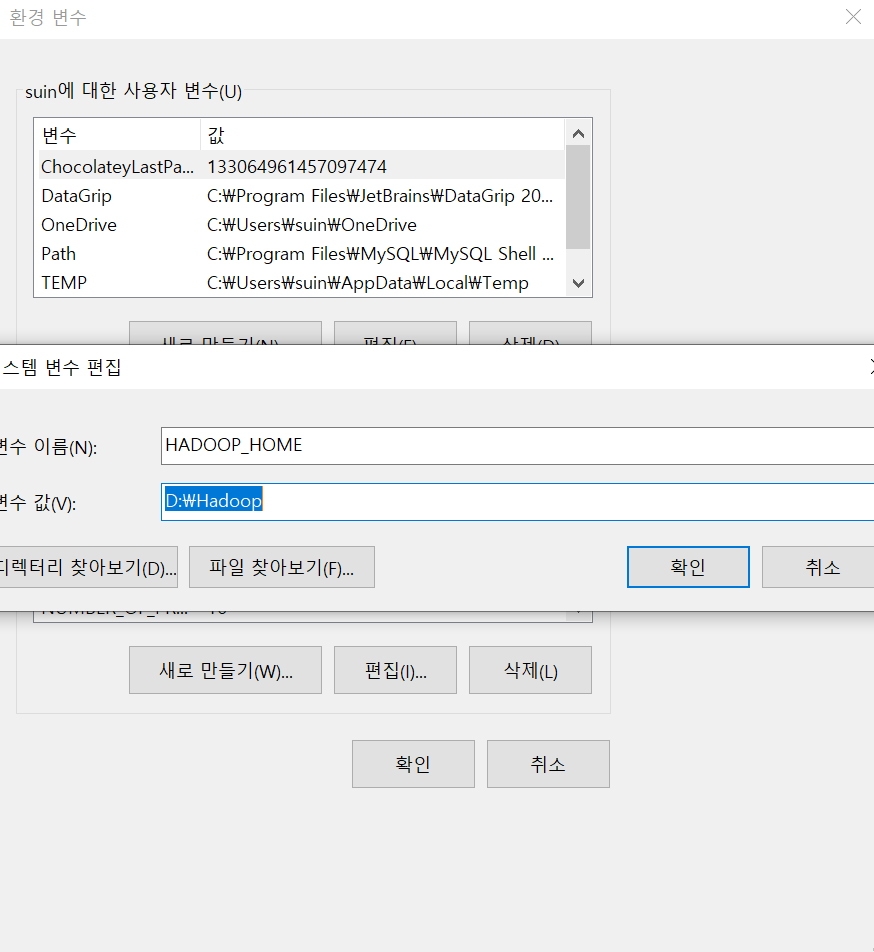
등록이 완료 되었으면 시스템 변수 내의 Path항목에 다음과 같이 추가해준다.

이제 정상적으로 스파크가 실행되는지 확인해보겠다.
명령 프롬프트를 실행해서 다음 명령어를 입력한다.
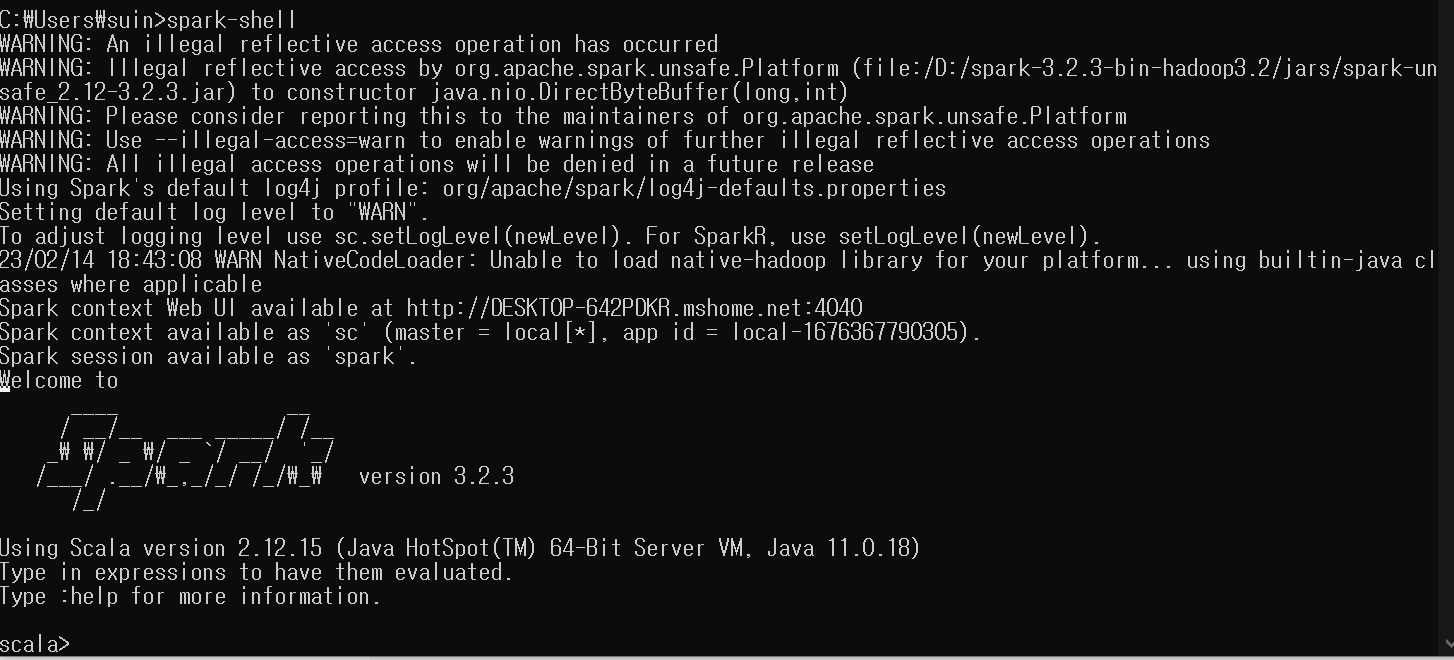
spark-shell
이 때, 다음과 같이 잘 출력되면 성공이다.
'Study > Data Engineering' 카테고리의 다른 글
| [Apache Spark] Dataframe의 Schema 지정하기 (0) | 2023.03.17 |
|---|---|
| [Apache Spark] "Python3" 명령어 실행 불가로 인한 오류 (0) | 2023.03.11 |
| [데이터 파이프라인 핵심 가이드] 2. 최신 데이터 인프라 (0) | 2023.02.08 |
| [airflow] Docker에서 airflow 환경 설정 및 실행하기 (1) | 2023.02.06 |
| [요리고 Airflow 도입기] 0. Airflow 사용을 결정한 이유 (0) | 2023.02.01 |



